
Index, veri tabanı tabloları üzerinde tanımlanan ve veriye daha az işlemle daha hızlı ulaşan veri tabanı nesneleridir. Indexler hakkında klasik bir örnek olarak telefon rehberi verilebilir. Telefon rehberindeki kayıtların sıralı olmaması durumunda, yani her kaydın telefon defterinde rastgele tutulması durumunda, arayacağımız bir isim için tüm rehberi gezmemiz gerekecek. Ama rehberinizdeki kayıtlar sıralı olsaydı, aradığımız ismin rehberin ortasındaki isimden ileride mi yoksa geride mi olduğuna bakabilirdik. Bu şekilde aradığımız verileri eleyerek bir kaç adımda istediğimiz sonuca ulaşabilirdik. Bu örnekteki gibi verinin sıralı tutulmasını sağlayan nesnelere index denir.
Index Prensibi
Bu kısımda index’lerin nasıl çalıştığına değineceğiz. Ama öncelikle sql serverda verilerin nasıl tutulduğuna bakalım.
Yeni bir veri tabanı oluşturduğumuzda veri tabanımızın bulunduğu dosyaları belirtiriz. Sql Server bu dosyaları fiziksel olarak değil mantıksal olarak 8 KB’lık bloklara böler. Bu bloklara page denir. Bundan dolayı dosyanın ilk 8 KB’ı page0, bir sonraki 8 KB’ı page1 olur ve bu şekilde devam eder. Page’lerin içinde ise tablolardaki satırlara benzeyen ve adına row denilen yapılar bulunur. Sql Server page’ler üzerinde başka bir mantıksal gruplama daha yapar; art arda 8 tane page’in bir araya gelmesiyle oluşan 64 KB büyüklüğündeki veri yapısına extent denir. Bir extent dolduğunda; bir sonraki kayıt, kayıt boyutu büyüklüğünde yeni bir extent’e yazılır.
{kind=link}
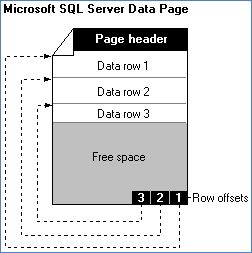
Her page içinde bulunan satır sayısı aynı değildir. Page’ler, veri büyüklüğüne göre değişen satırlara sahiptir ve bir satır sadece bir page içinde olabilir. Sql Server aslında satırları okumaz bunun yerine page’leri okuyarak verilere ulaşır.


Sql Server’da bir tabloya index tanımlandığı zaman o tablodaki verileri aşağıdaki gibi bir tree yapısına göre organize eder.
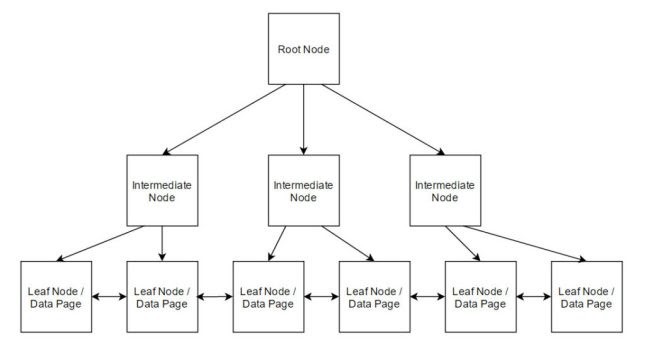
Bu tree yapısının en üst node’u Root level diye adlandırılır. Aslında buradan başlayarak rehber örneğinde olduğu gibi sağa veya sola dallanarak kaydı bulmaya çalışır. Root level’in bir altında ise Intermediate level’ler vardır. Bir tane Root level olması gerekirken, Intermediate level’ler ise tablodaki veri sayısına göre birden fazla olabilir. En alt kısımda ise Leaf Node’lar yani veriyi asıl tutan yapılar vardır. Aramaya en üstten başlanıp en alt level’a kadar gelinir. Index tipine göre leaf node’larda tutulan veri değişiklik gösterecektir.
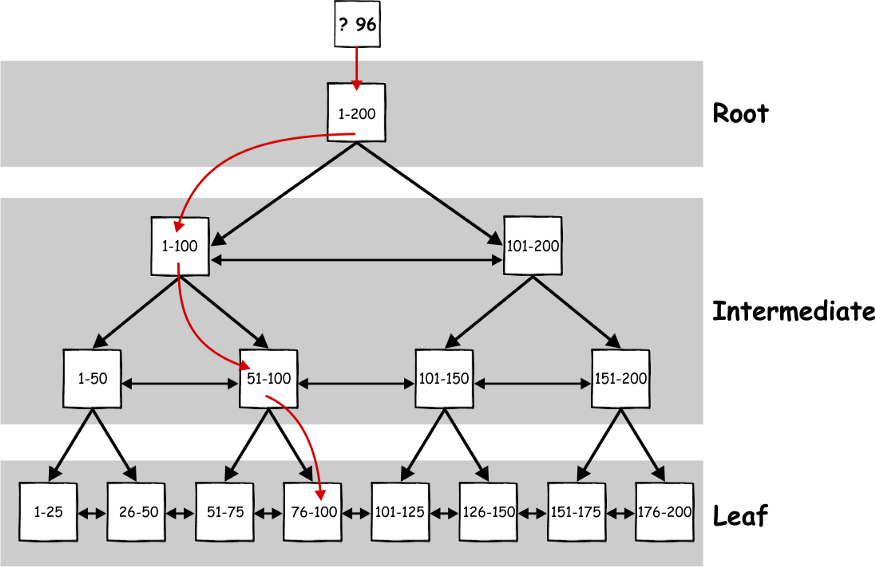
Yukarıdaki resimde görüldüğü gibi aradığımız veriyi üç adımda bulabiliriz. Ama index kullanılmasaydı, yani veriler yukarıdaki gibi tree yapısında organize edilmeseydi tüm kayıtlar gezilerek veriye ulaşabilirdi. Veriye ulaşmak için her zaman leaf level’a kadar inmek gerekir.
Heap Table
Sql Server’da heap table adında bir kavram yok. Bir tabloya heap denilmesi aslında onun üzerinde bir index tanımlı olup olmamasına bağlıdır. Sql Server bir veriyi indexsiz bir tabloya eklerken sıralı olarak diskte tutmaz ve veriler rastgele data page’lere yazılır. Bu şekilde olan tablolar heap diye adlandırılır. Yani üzerinde clustered index olmayan tablolar heap table’dır diyebiliriz. Heap table üzerinde bir veri arandığında Sql Server tablonun kayıtlarına sırayla erişir ve aradığımız kayıtla eşleştirir. Kayıt bulunsa bile eşleşebilecek başka kayıt var mı diye tüm kayıtlarda karşılaştırma işlemi yapar. Sql Server’ın yaptığı bu işleme Table Scan denir. Bu işlem tablodaki kayıt sayısına göre çok uzun zaman alacaktır. Clustered Index tanımlı olan tablolara göre avantajları da vardır. Bu tablolarda ekstra index bakım maliyeti ve clustered index tree yapısı için ekstra alana ihtiyaç yoktur.
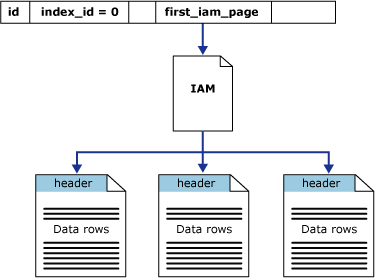{kind=link}
Clustered Table
Üzerinde clustered index tanımlı tablolara denir. Sorgu index tanımlanmış kolonları kullanırsa, veriye çok hızlı erişim sağlanır. Data page’ler veriye hızlı erişim için birbirine bağlıdır. Heap table’lara göre INSERT, UPDATE ve DELETE işlemlerinde ekstra index bakım maliyeti vardır.
Index Çeşitleri
Sql Server’da indexler temelde clustered ve non-clustered index olmak üzere ikiye ayrılır. Leaf node’larda tutulan verinin kendisi ise clustered, verinin hangi pagede tutulduğunu gösteren pointer ise non-clustered index diye adlandırılır.
Clustered Index
Yukarıda da bahsettiğimiz gibi, clustered index’ler tablodaki veriyi fiziksel olarak sıralar. Bir tablo fiziksel olarak sıralandığından tablo üzerinde sadece bir tane clustered index tanımlanabilir. Clustered index için seçilecek kolon veya kolonlar sorgulardaki en fazla kullanılan kolonlar olmalıdır. Veriler, bu kolonlara göre fiziksel olarak sıralanacağından çok hızlı erişilir. Ayrıca seçilen kolonun çok değiştirilmeyen bir alan olması gerekir. Çünkü index’e ait kolonun değişmesi demek tüm index’in yeniden organize olması yani fiziksel olarak yeniden sıralanması anlamına gelir. Sql server index ihtiyacını aslında kendisi belirler. Bizim tanımlayacağımız index’leri kullanıp kullanmamaya kendisi karar verir.
CREATE CLUSTERED INDEX IX_IndexName ON TableName (Column1);
Non-Clustered Index
Non-Clustered Index veriyi fiziksel değil mantıksal olarak sıralar. Bu index’lerin leaf node’larında verinin kendisi değil nerede olduğu bilgisi tutulur. Tablo üzerinde en fazla 999 tane non-clustered index tanımlanabilir. Non-clustered index’ler veriye doğrudan erişemez. Heap üzerinden ya da bir clustered index üzerinden erişebilir. Bu index’i oluştururken sorgumuzun koşul kısmında sık kullandığımız kolonlardan oluşturulması gerekir.
CREATE NONCLUSTERED INDEX IX_IndexName ON TableName (Column1);
Bir tabloda en fazla bir tane clustered index, 999 tane de non-clustered olabilir demiştik. Sql Server’da bir index en fazla 16 kolon içerebilir ve toplam boyutu 900 byte’ı aşmaması gerekir. Ayrıca büyük boyutlu alanlar yani varchar(max), nvarchar(max), xml, text ve image türüne sahip kolonlar üzerinde herhangi bir index tanımlaması yapılamaz. Hep index’in avantajlarından bahsettik ama maliyetleri de çok fazladır. Her index oluşturduğunuzda veri tabanınızdan bir alan işgal edilir. Index’lerin insert, update ve delete işlemlerinde tekrardan organize olması gerekir ve bu durum tablo performansını olumsuz etkiler. Bir tabloda index oluşturulmaya başlandığında Sql Server tabloyu kitler ve erişimi engeller. Index oluşturma işlemi tablodaki veri sayısına göre kısa veya uzun sürebilir. Dolayısıyla index seçiminde çok düşünüp dikkatli karar vermeliyiz.
Unique Index
Verinin tekilliğini sağlamak için kullanılır. Veri tekrarını engeller ve tanımladığımız kolona göre veri çekmeyi hızlandırır. Tablomuza bir primary key veya unique constraint tanımladığımız zaman otomatik unique index tanımlanır. Bu index’i birden fazla kolona tanımladığımız zaman tekillik tek kolon üzerinden değil de tanımlandığı kolonlar üzerinden oluşuyor. Tanımlandığı kolona sadece bir kere null değeri eklenebilir. Hem clustered hem de non-clustered index’ler unique olarak tanımlanabilir.
CREATE UNIQUE INDEX AK_IndexName ON TableName (Column1);
Filtered Index
Bu index türünde ise tüm tabloya index tanımlamak yerine, belirlenen koşula uyan veriye index tanımlanır. Hem performansı arttırır hem de index bakım maliyeti düşük olur. Normal bir non-clustered index’e göre daha az yer kaplar.
CREATE NONCLUSTERED INDEX IX_IndexName ON IndexName (Column1, Column2) WHERE …
Composite Index
Tablo üzerinde tanımlanan index tek kolon üzerinden değil de birden fazla kolon üzerinden tanımlandıysa bu index türüne composite index denir. Index kısıtlamalarında bahsettiğimiz gibi, bir tabloda en fazla 16 kolona kadar composite index tanımlanır ve 900 byte sınırını geçmemelidir. Hem clustered hem de non-clustered index’ler composite olarak tanımlanabilir. Bu index tanımında kolonların hangi sırada yazıldığı da çok önemlidir. Index performansının artması için çeşitliliği fazla olan kolon başa yazılmalıdır. Yani tablodaki verilere göre tekil veri sayısı fazla olan kolon başa yazılır.
CREATE NONCLUSTERED INDEX IX_IndexName ON IndexName (Column1, Column2)
Covered Index
Öncelikle bu index türüne neden ihtiyaç duyduğumuzu açıklayalım. Normalde bir sorguda erişmek istediğimiz alanlar index tanımında mevcut ise bu index ile birlikte veriye direkt olarak leaf node’lardan ulaşabiliriz. Ama index tanımından farklı bir kolon veya kolonları çekmek istediğimiz zaman, öncelikle index koşuluna uyan veriler çekilir ve key değeri belirlenir. Daha sonra bu key değeri üzerinden index’te tanımlı olmayan kolonların değerlerine erişilir. Bu işleme key lookup denir.
Sql Server veriye erişmek için fazladan bir key lookup işlemi yapar ve bu da I/O performansını olumsuz etkiler. Neden composite index tanımlamıyoruz diye sorabilirsiniz. Composite index’te 16 kolon ve 900 byte sınırı olduğundan istediğimiz kadar kolon ekleyemeyiz. Kısıt olmasa dahi, index tanımımızda fazla kolon olması index boyutunu o kadar arttıracaktır ve yapılacak update, insert gibi işlemlerde index yeniden organize olacağından performans kaybına yol açacaktır.
Bu problemin çözümü için covered index’ler kullanabiliriz.
CREATE NONCLUSTERED INDEX IX_IndexName ON TableName (Column1) INCLUDE (Column2, Column3);
Index tanımında belirtilen INCLUDE seçeneği ile index dışında kalan ve sorgumuzda bulunan kolonları ekleyebiliriz. Sql Server bu veriye erişirken ekstradan bir key lookup işlemi yapmaz ve doğrudan erişir. INCLUDE seçeneği ayrıca bazı kısıtlamaları da ortadan kaldırır. Hatırlarsanız büyük boyutlu veri tutan varchar(max), nvarchar(max), xml, text ve image gibi alanları index tanımına ekleyemiyorduk. INCLUDE seçeneği ile eklenebilir. Ayrıca 16 kolon ve 900 byte kısıtı da ortadan kalkmış oluyor. INCLUDE seçeneği sadece non-clustered indexlerle tanımlanabilir.
Mümkün olduğunca sorgularımızda az sütun seçmeye özen göstermeli ve select * ifadesinden kaçmalıyız. Index’lerin include kısmını sütunlarla doldurmadan önce maliyeti hesaplayıp buna göre index tanımlamalıyız. Aksi taktirde sorgularımızın performansı daha düşebilir.
Column Store Index
Şimdiye kadar açıkladığımız index türlerinde index’ler satır bazlı tutulur. Bu index türünde ise kolon bazlı indexleme yapılır. Diğer index’lere göre depolama maliyeti düşüktür. Genelde verinin daha az yazılıp daha çok okunduğu sistemlerde ve karmaşık filtreleme ve gruplama işlemlerinin yapıldığı veri ambarı gibi büyük veri içeren uygulamalarda kullanılır. Non-clustered index’e göre 15 kata varan daha fazla sıkıştırma yapar ve sorgularda 10 kata kadar performans artışı sağlar.
CREATE COLUMNSTORE INDEX IX_IndexName_ColumnStore ON TableName (Column1, Column2);
Full-text Index
Sql Server’da metin tabanlı aramalarda, like operatörünün performansı özellikle metin boyutu büyüdükçe düşmektedir. Bunun dışında index kısıtlamalarında bahsettiğimiz gibi 900 byte sınırı da index oluşturmamızı kısıtlar. Özellikle büyük boyutlu veri içeren alanlarda (varchar(max), nvarchar(max), xml, text) hızlı arama yapabilmek için bu index türünü kullanabiliriz. Aslında bu Sql Server’ın sunduğu bir servistir. Başlı başına bir makale konusu olduğundan daha fazla detaya girmeyeceğim.
Index Tasarımı
Bu bölüme kadar index çeşitlerinde nasıl tanımlama yapılması gerektiğine değindik. Bunları özet olarak toplarsak;
- Yoğun şekilde veri güncelleme işlemi olan tablolarda, index tanımında mümkün olduğunca az kolon seçmeliyiz.
- Veri güncellemenin az olduğu tablolarda daha çok index tanımlayabiliriz.
- Clustered index’i mümkün olduğunca az kolona tanımlamalıyız. İdeal tanımlanma biçiminde clustered index’imiz unique olan kolonda tanımlanmalı ve null değeri içermemeli.
- Index tanımladığımız kolonda ne kadar tekrarlı veri varsa index performansımız düşük olacaktır.
- Composite index’lerde kolonların sırasına dikkat etmeliyiz.
- Computed kolonlara da gereksinimleri karşıladıkça index tanımlanabilir. Yani compute edilen değerin deterministik olması gerekir.
- Depolama ve sıralama etkileri nedeniyle index tanımlarında kolonlar dikkatli seçilmelidir.
- Index tanımında kolon sayısı, yapılacak insert, update ve delete işlemlerinde performansı direkt olarak etkileyecektir.
Bu maddelerin dışında bu linkten daha detaylı bilgilere ulaşabilirsiniz.
Index Operasyonları
Index’ler performansa her zaman olumlu katkı sağlamaz ve olumsuz yönde de etkileyebilir. Index’lerin kullanılmadığını fark ettiğimizde performansı olumsuz etkilememesi için ya silmemiz ya da pasif yapmamız gerekebilir.
- Indexlerin pasif yapılması; index tanımlama bilgisini sistem kataloglarından silmez ama index’in içerdiği asıl veriyi siler. Non-clustered index’in pasif yapılması sadece index’e ulaşımı engeller ama clustered indexlerde ise drop veya rebuild etmedikçe tablonun verisine ulaşımı engeller. Index’i kısa süre için silip tekrar oluşturmamız gerekiyorsa bu seçeneği kullanabiliriz.
ALTER INDEX INDEX IX_IndexName ON TableName DISABLE
- Indexlerin silinmesi; clustered index’ler silindiğinde leaf node’larda tutulan veri, sıralanmamış heap table’larda tutulmaya başlanır. Hem tanımla bilgisi hem de index’in verileri diskten silinir. Primary key olarak tanımlanan clustered index silinemez. İlk önce tablodaki bu constraint kaldırılmalıdır.
DROP INDEX INDEX IX_IndexName ON TableName
Index Seçenekleri
Index’leri oluştururken bazı seçenekler kullanırız. Bunlar aşağıdaki gibidir;
FILLFACTOR: Verilerin tutulduğu leaf node’lardaki data page’lerin yoğunluğunu ayarlamak için kullanılır. Gelen yeni kayıtlar page’lere yazılırken doluluk oranı kontrol edilir, yer varsa ilgili page’e yoksa page ikiye bölünür ve yeni gelecek veri için organize edilir. Bu pagelerin doluluk oranını FILLFACTOR ile ayarlıyoruz. Varsayılan değer sıfır olup tüm data page’ler doldurulur. Fillfactor’ün büyük tutulması page sayısını arttıracaktır. Verileri okurken daha çok veriye daha az page okuyarak ulaşırız. Bu değerin az tutulması yani page’lerin boş bırakılması ise insert işleminde bize performans kazandıracaktır. Her iki durumda da olumlu ve olumsuz yanı olduğundan bu değer iyi hesaplanmalıdır.
PAD_INDEX: Fillfactor değeri leaf node’larda uygulandığını söylemiştik. Bu değerin Intermediate seviyesindeki node’lara da uygulamak istersek fillfactor seçeneği ile birlikte pad_index seçeneğini de kullanmalıyız.
SORT_IN_TEMPDB: Bu seçeneğin aktif edilmesi index işlemlerimizin veri tabanında değil de Tempdb sistem veri tabanında olacağı anlamına gelir.
IGNORE_DUP_KEY: Bu seçenekle unique index tanımlı tabloya aynı kaydı tekrar eklediğimizde hata mesajının seviyesini düşürerek uyarı verilmesini sağlar. Kayıt eklenmez ama işlem bir transaction içinde ise transaction sonlanmaz diğer işlemlere devam edilir.
DROP_EXISTING: Oluşturulmak istenen index adı ile aynı isimde yeni bir index oluşturulmak istediğinde kullanılır. Eski index’i silip yenisini oluşturur.
ONLINE: Index oluştururken tablonun kitlendiğini söylemiştik. Bu seçenek ile index oluşurken tablo kitlenmez ve veriye erişim sağlanır.
MAXDOP: Bu seçenek ile index oluşturma işlemi için sunucumuzdaki işlemcilerden kaç tanesini kullanacağını belirtebiliriz. Bu değer en fazla kullanılacak işlemci değerini belirtir.
DATA_COMPRESSION: Bu seçenek ile özellikle büyük boyutlu index’lerin oluşurken index’imize ait verilerin sıkıştırılmasını sağlar.
Bunlar sık kullanılan index seçenekleridir. Seçeneklerin tamamına burada yer vermedim. İlgilenenler bu linki inceleyebilir.
Index’ler hakkında daha konuşulması gereken çok şey var. Ben bir geliştirici gözünden kullandıklarımı anlatmaya çalıştım.